
NVIDIA GPUDirect Storage
Published:
 출처: https://developer.nvidia.com/blog/gpudirect-storage/
출처: https://developer.nvidia.com/blog/gpudirect-storage/
GPU는 우리 생활에서 정말 많이 사용됩니다. 원래의 목적인 그래픽 연산에서부터 인공지능 학습까지, 과거에 비해서 훨씬 다양한 분야에서 사용되고 있는데요. 데이터베이스 분야에서 GPU는, 적어도 제가 아는 한에서는 일종의 애증의 관계였습니다. 먼저 GPU를 사용하는 데 있어서 생기는 문제점을 살펴보도록 하겠습니다.
이 포스팅에서 저는 컴퓨터 본체의 메모리를 시스템 메모리 혹은 호스트 메모리로, NVMe 저장소를 그냥 저장소 혹은 스토리지 등으로 일컫습니다. 이 점에 혼동 없으시길 바랍니다.
GPU는 왜 느린가
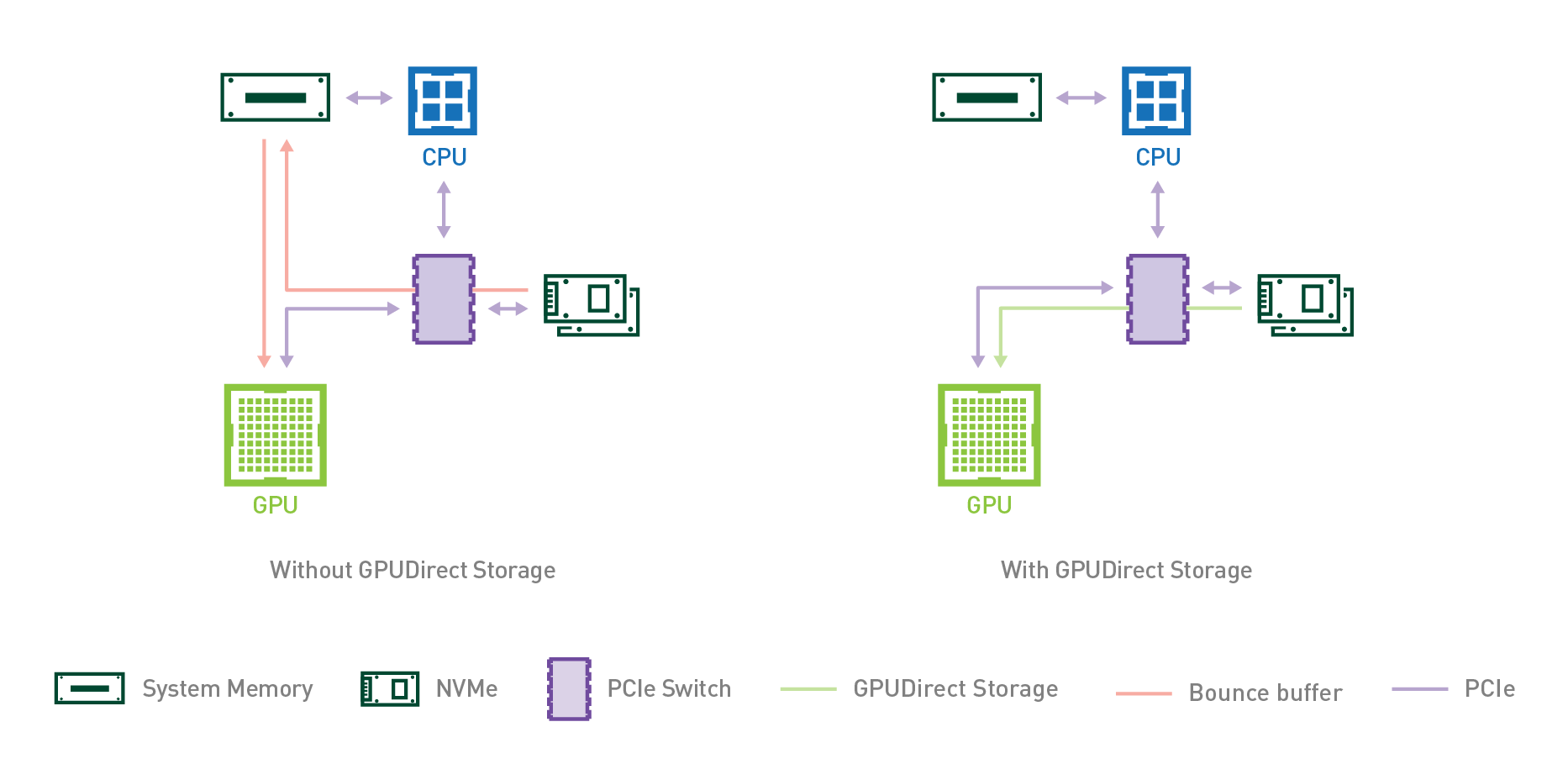
분명 GPU의 강력한 병렬 연산 기능은 데이터베이스를 가속화하는 데에 도움이 될 수 있지만, 이 과정에 큰 문제가 하나 있습니다. 바로 GPU가 호스트 시스템에 종속적이라는 것입니다. 이게 무슨 뜻이냐면, 예를 들어서 GPU 연산을 하려고 할 때 그 데이터를 우선 호스트 메모리에 로드한 뒤, 그 데이터를 PCI-Express(PCIe)를 통해서 GPU 메모리로 옮겨온 뒤에야 GPU 연산을 할 수 있다는 것입니다. 이 과정에서 CPU 연산 자원과 호스트 메모리의 공간이 소모되는 등 불필요한 과정이 너무 많이 끼어듭니다. 뿐만 아니라 GPU를 연결하는 PCIe가 상당한 병목현상을 유발하는데, 초당 데이터 전송률이 GPU의 연산 속도에 훨씬 미치지 못해 너무 비효율적인 것입니다.
전체적인 과정은 위 그림의 좌측 도식에서 확인하실 수 있습니다. 우선, CPU 연산을 통해 우측의 NVMe 저장소에서 데이터를 시스템 메모리, 즉 호스트 메모리로 로드합니다. 이 과정에서 시스템 메모리에 할당되는 버퍼를 바운스 버퍼(bounce buffer)라고 부르며, 두 장치 사이의 데이터 전송을 위해 일시적으로 할당되는 버퍼를 의미합니다. 그 다음, CPU 연산을 통해 시스템 메모리에 있는 데이터를 GPU 메모리로 전송합니다. 이렇게 GPU 메모리에 데이터가 로드 된 뒤에야 연산을 수행할 수 있게 되는 것입니다.
정리하자면 GPU를 사용하는 데에는 다음과 같은 문제가 있습니다.
- 데이터를 옮기는 과정을 지시하는 CPU 연산
- 전송되는 데이터를 저장하는 바운스 버퍼로 인한 시스템 메모리 공간 소모
- 전체적으로 데이터를 전송하는 데 쓰이는 PCIe 버스의 전송 속도의 한계
GPU 자체는 굉장히 빠른데, 이런 시스템적인 한계 때문에 사용이 꺼려졌던 것입니다. (그럼에도 불구하고 GPU를 효율적으로 사용하려는 노력은 계속되어 왔습니다. )
NVIDIA GPUDirect Storage
이런 문제를 해결할 수 있을까 고민을 했었는데, 조사를 잠깐 하면서 찾아낸 것이 NVIDIA GPUDirect Storage입니다. NVIDIA에서 제작하는 GPUDirect 시리즈의 일환이라고 하는데, 이것에 대해서 공부한 것을 조금 정리하고자 합니다.
GPUDirect
GPUDirect Storage를 알아보기 전에 먼저 GPUDirect에 대해서 간단하게 알아봅시다. GPUDirect 공식 홈페이지에 가면 GPUDirect에 대해 다음과 같은 설명을 합니다.
NVIDIA GPUDirect is a family of technologies, part of Magnum IO, that enhances data movement and access for NVIDIA data center GPUs.
즉 GPUDirect란 NVIDIA에서 제작한 데이터센터용 GPU 사이의 데이터 이동과 접근을 수월하게 만들어 주는 기술의 총칭이라고 볼 수 있습니다. 대표적으로 CPU와 시스템 메모리를 거치지 않고 NIC에서 GPU 메모리로 데이터를 송수신하는 GPUDirect RDMA, 다수의 GPU 메모리 간에 데이터를 주고받을 수 있게 하는 GPUDirect Peer to Peer 등이 있습니다. 그 중에서 GPUDirect Storage는 비교적 최근에 소개된 기술입니다.
GPUDirect Storage?
GPUDirect Storage(GDS)란 앞서 말했듯 GPUDirect 기술의 일부입니다. GPU의 데이터 이동을 강화하는 기술들 중에서도 GDS는 스토리지와의 직접적인 데이터 이동을 담당하는 기술입니다. 여기서 제약이 하나 있는데, 그냥 아무 저장소와 직접적인 데이터 이동이 가능하게 하는 것이 아니라 NVMe 저장소와만 직접적인 연결이 가능하다는 것입니다.
앞서 GPU를 사용하는 데에 세 가지 문제가 있다고 했습니다. 그렇다면 GDS는 이 문제 중에서 어떤 문제들을 해결한 것일까요?
우선, 저장소에서 시스템 메모리로 데이터를 가져오는 연산을 할 필요가 없어집니다. 따라서 첫 번째 문제인 불필요한 CPU 연산을 제거할 수 있죠. 또한, 시스템 메모리로 불러온 데이터를 임시로 저장할 바운스 버퍼를 둘 필요가 없어집니다. 따라서 두 번째 문제인 불필요한 메모리 공간 소모 문제도 사라집니다. 하지만 결국 GPU에 데이터가 가긴 해야 하는데, 그 과정에서 PCIe 버스를 통하지 않으면 갈 수 없기 때문에 세 번째 문제인 PCIe 버스의 전송 속도의 한계는 넘어서지 못합니다.
이와 관련된 내용은 다음 논문에서 확인할 수 있습니다.
출처: Bayati, Mahsa, Miriam Leeser, and Ningfang Mi. “Exploiting GPU Direct Access to Non-Volatile Memory to Accelerate Big Data Processing.” 2020 IEEE High Performance Extreme Computing Conference (HPEC). IEEE, 2020.
GPU를 사용해 Apache SPARK의 연산을 강화한 SPARK-GPU에 GDS를 적용했을 때의 성능을 비교한 논문입니다. 이 논문을 보시면 다음과 같은 결과가 있습니다.
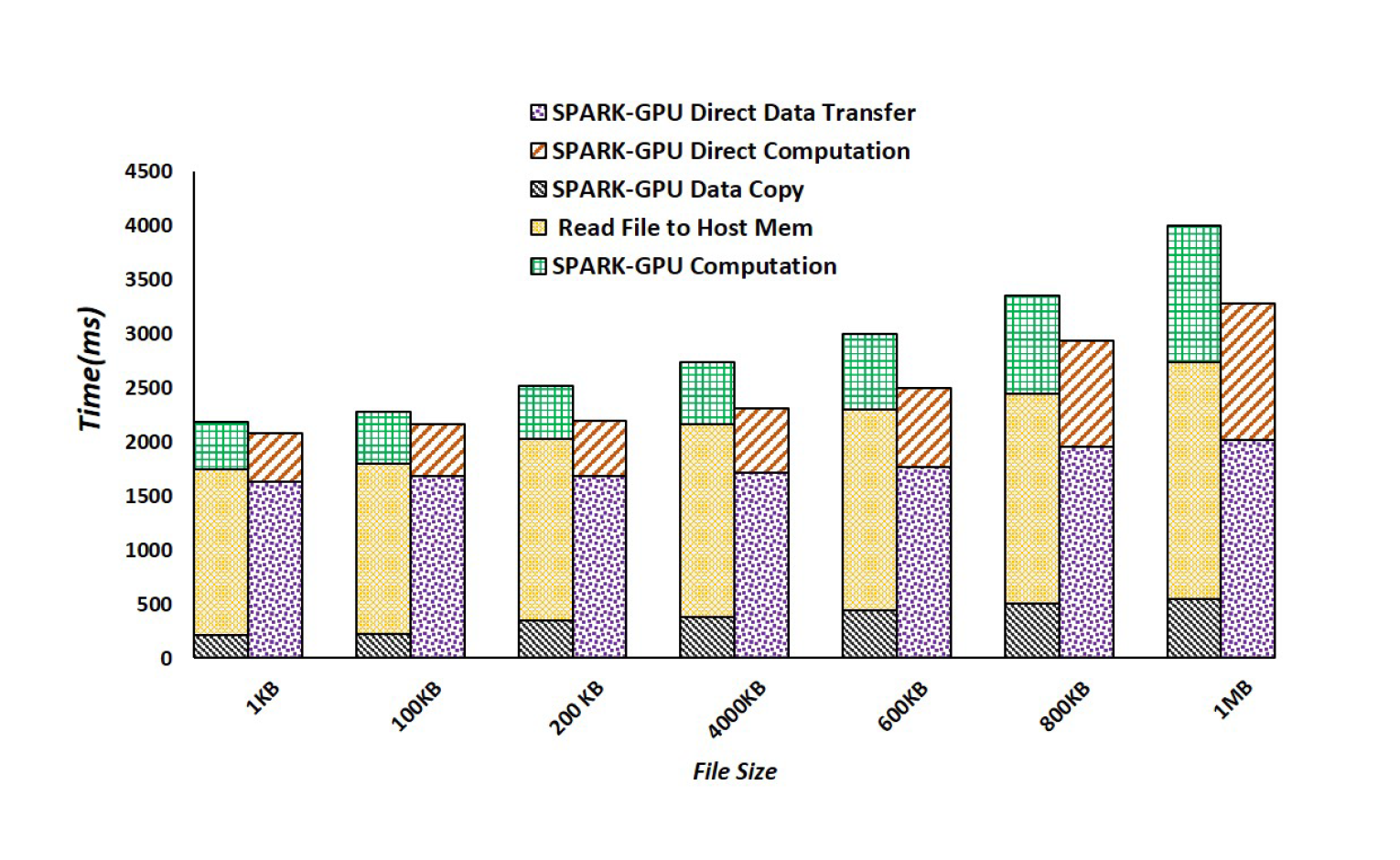
두 막대그래프 중에서 좌측 막대그래프가 GDS를 적용하지 않은 SPARK-GPU, 우측 막대그래프가 GDS를 적용한 SPARK-GPU의 작업 시간입니다. GDS를 적용한 SPARK-GPU의 연산 속도가 상대적으로 빠른 것을 알 수 있습니다. 그 외에도 세부적으로 논의할 만한 내용은 다음과 같습니다.
- 상단의 초록색과 빨간색 빗금이 칠해진 부분이 GPU에서 연산이 실행되는 시간을 나타냅니다. 동일한 GPU 연산이다 보니 GDS 적용과 관계 없이 시간이 동일함을 알 수 있습니다.
- 하단의 검은색 빗금이 칠해진 부분이 CPU-GPU 간의 데이터 전송 시간을 나타냅니다. 생각보다 차지하는 비율이 적은데, 순수하게 CPU-GPU 간의 데이터 전송이 관측된 부분만 저 만큼이고, 일부분은 저장소에서 시스템 메모리로 데이터를 읽어오는 시간에 중첩되었을 것이라고 추측됩니다.
- 노란색 빗금과 보라색 빗금이 칠해진 부분은 저장소에서 각각 시스템 메모리로 데이터를 불러오는 시간과 GPU 메모리로 데이터를 불러오는 시간을 나타냅니다. 이 두 시간이 거의 동일한 것을 알 수 있습니다. 시스템 메모리로 가져오든 GPU 메모리로 가져오든 똑같이 PCIe 버스를 통해서 와야 하기 때문으로 추측됩니다.
논문에 따르면 GDS를 사용하는 것이 약 35%의 전송 속도 향상을 가져왔으며, 실행 시간 전체로는 약 20%의 성능 향상을 이루었다고 합니다.
Conclusion
GPUDirect 시스템 자체는 매우 매력적인 기술이라고 생각합니다. 특히, 발표된 후 시간이 꽤 지난 GPUDirect RDMA와 같은 경우는 이미 많은 연구와 개발이 진행되었을 정도로 많은 영향을 미친 것으로 알고 있습니다. 상대적으로 최신 기술인 GDS 역시 RDMA 못지 않은 많은 가능성을 가진 기술이라고 생각합니다. 비록 PCIe 버스를 통한 연결이 필수적이라는 태생적인 한계가 있지만, CPU와 메모리 적으로도 많은 도움이 될 수 있는 기술임에는 틀림없습니다. 이 기술 자체를 발전시키는 연구보다는 (하드웨어적인 노력이 많이 필요하기 때문에) 이 기술을 어떻게 적용할지를 연구하는 것이 바람직하다고 생각됩니다.